7 min de lecture
Résumé
Cette recherche vise à découvrir les algorithmes d'analyse des sentiments les plus efficaces tout en mettant l'accent sur la neutralité, la non-partialité et l'impartialité dans notre évaluation. En utilisant le score F1 comme mesure d'évaluation fondamentale, notre étude examine rigoureusement les performances de divers modèles d'analyse des sentiments par le biais d'une analyse comparative. Notre objectif principal est d'identifier des algorithmes qui excellent dans le discernement impartial et impartial des sentiments dans un texte en langage naturel. À travers cette analyse, nous visons à identifier les solutions les plus performantes adaptées à des applications pratiques, en garantissant une évaluation juste et impartiale.
Quels en sont les principaux résultats ?
Méthodologie
L'échantillonnage
Les révisions utilisées pour entraîner et tester les modèles ont toutes été générées par ChatGPT 3.5 afin d'utiliser des exemples inédits, garantissant qu'aucun des modèles testés (ni ceux de Lettria) ne pouvait être entraîné sur ces données.
Distribution
Les 17 374 avis générés par ChatGPT sont également équilibrés entre 3 sentiments : positif (POS), neutre (NEU) et négatif (NEG) selon la distribution suivante :

Évaluation des résultats
Dans cette étude, nous utilisons le score F1 comme indicateur clé pour évaluer les performances de notre modèle d'analyse des sentiments, en le comparant aux modèles existants. Le score F1, qui harmonise précision et rappel, est un outil essentiel pour évaluer la précision du modèle et sa capacité à classer correctement les sentiments dans un texte en langage naturel, ce qui en fait une référence fiable pour les comparaisons.
Le score F1 de l'apprentissage en profondeur de la PNL quantifie les performances du modèle en équilibrant précision et rappel, ce qui est crucial pour des tâches telles que l'analyse des sentiments ou la classification de texte. Il harmonise ces mesures en une seule valeur, ce qui facilite l'évaluation du modèle.
Des résultats détaillés
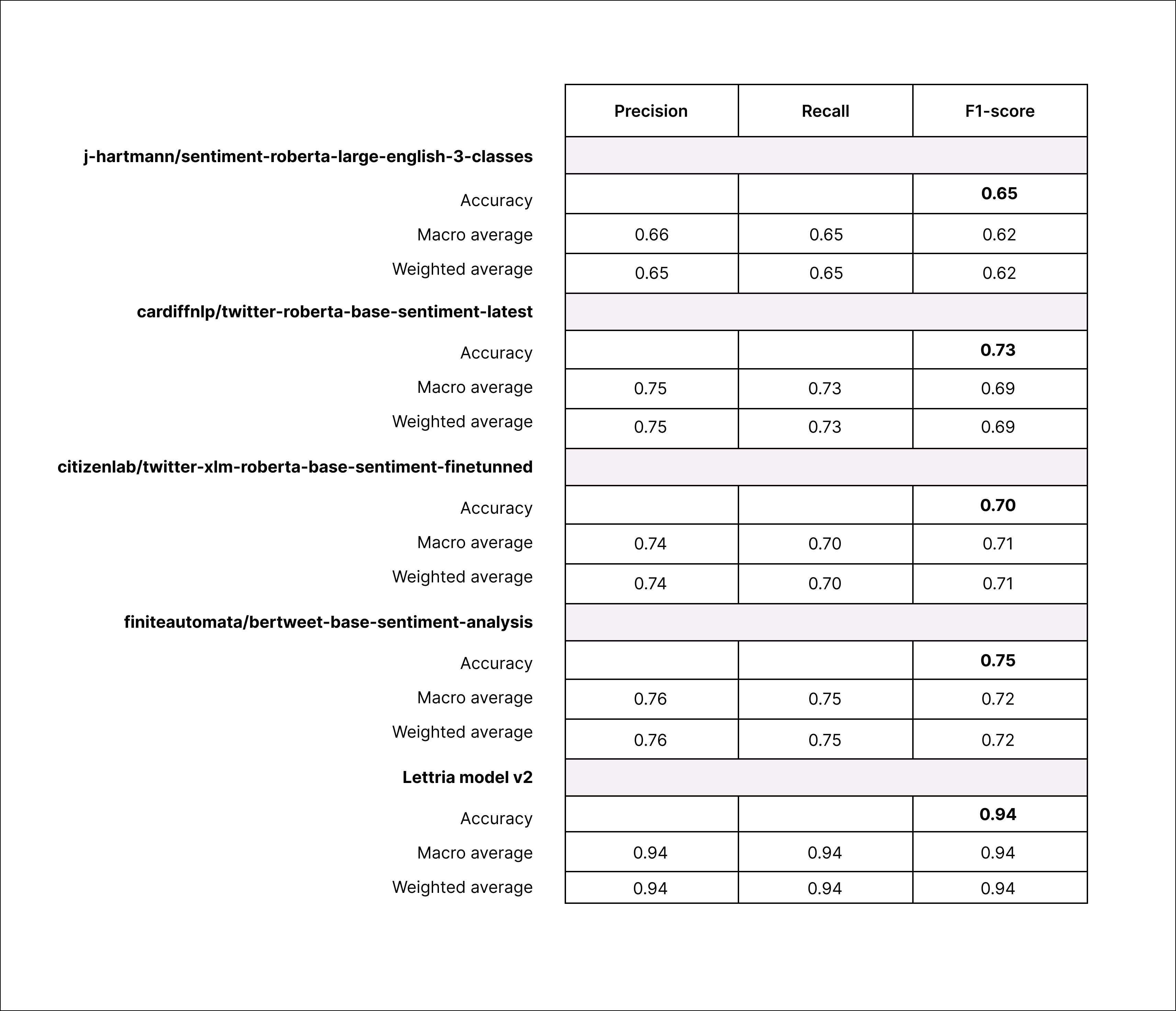
Mises en garde
L'analyse comparative des modèles d'analyse des sentiments sur un échantillon généré d'avis comporte certaines réserves. Tout d'abord, le texte généré peut ne pas représenter fidèlement les sentiments du monde réel, ce qui peut entraîner des évaluations biaisées ou irréalistes. Deuxièmement, un surajustement du modèle peut survenir si les données générées ressemblent étroitement aux données d'entraînement. De plus, les données synthétiques peuvent ne pas présenter les nuances et le contexte présents dans les revues authentiques, ce qui affecte la généralisation du modèle. Par conséquent, bien qu'il constitue un point de référence initial utile, il doit être complété par des évaluations sur des données réelles afin de garantir des performances robustes du modèle.
Données ouvertes
L'ensemble de données utilisé pour notre analyse est accessible au public et peut être téléchargé via le lien suivant : Téléchargez l'échantillon.
Cet ensemble de données ouvert a non seulement assuré la reproductibilité de nos recherches, mais a également encouragé une participation et un examen plus approfondis au sein de la communauté des chercheurs.
Les initiatives de données ouvertes comme celle-ci servent de catalyseurs au progrès scientifique, permettant aux chercheurs de tirer parti des travaux des autres chercheurs, pour finalement faire avancer le domaine de l'analyse des sentiments et du traitement du langage naturel dans son ensemble.