.png)
.png)
9 min
UPDATE: Discover how Lettria’s Ontology Toolkit v2 outperforms handcrafted ontologies.
Introduction
Creating an ontology has long been a complex, expert-driven task, one that requires deep domain knowledge and significant manual effort. With Ontology Toolkit, Lettria introduces a fully automated solution that builds ontologies directly from your documents, turning unstructured information into structured, machine-readable knowledge. This breakthrough not only saves time but also paves the way for scalable data exploration, knowledge graphs, and next-generation agentic AI systems.
1. Why ontology matters
1.1. What is an ontology
An ontology is a structured representation of information related to a specific domain. It defines classes (concepts) and properties (relationships and attributes) that describe how entities are connected and characterized.
Unlike a simple taxonomy or database schema, an ontology captures meaning. It encodes how things relate to one another and allows systems to reason over data rather than just store it. Ontologies are a cornerstone of semantic technologies, making data interoperable, interpretable, and reusable across contexts.
1.2. A core asset for representing business information
In an enterprise context, ontologies serve as a backbone for knowledge organization. They allow information scattered across reports, regulations, and operational documents to be modeled consistently.
For instance, in pharmacology, ontologies model the relationships between drugs, molecules, diseases, and clinical trials. They make it possible to link scientific literature with structured databases, improving drug discovery and knowledge sharing between research teams.
Consider also the example of the CSRD (Corporate Sustainability Reporting Directive), which imposes a framework on companies concerning the environmental, social and governance aspects of their activities. In this case, an ontology can structure sustainability metrics, indicators, and relationships between entities such as companies, activities, and environmental impacts. This enables organizations to align data from various departments and automatically generate compliant reports.
Across both examples, ontologies serve as a shared semantic layer, a bridge between textual data and machine-understandable knowledge. And this can be applied to all areas of activity.
1.3. A complex and time-consuming task
Building an ontology from scratch is a labor-intensive process. It requires both technical expertise in ontology engineering and deep domain knowledge. Moreover, existing public ontologies rarely match the specific needs of a company’s activities or data organization.
As a result, teams often must create or adapt custom ontologies, or ask specialists to create them manually, processes that can take months or years. This complexity is precisely what motivated the creation of Lettria’s Ontology Toolkit, an automated solution designed to streamline and accelerate ontology generation.
2. Ontology Toolkit: automating ontology creation
2.1. From documents to ontologies: how we designed it
Ontology Toolkit was built to automatically generate ontologies directly from an organization’s documents. In the case of pharmacology, this may include drug inserts or clinical trial results. For the CSRD, these will be the company's annual reports.
The process begins with document preprocessing and parsing, ensuring that the text is properly segmented and normalized. This step has been designed to ensure that all the information in a document can be represented, including that contained in tables, graphs, and diagrams, which are common and crucial in professional documents.
Once prepared, the documents are processed by a LLM (Large Language Model) with the relevant use case. In this context, a use case is a sentence that describes the situation in which a specific consumer uses a solution to meet a need, in order to guide information processing. For example, for the CSRD ontology, the use case is “Organizing CSRD reports into structured data (metrics, year results, governance, risks, targets, etc.) to support AI-driven analysis and compliance.”
Then, a set of dedicated engineered prompts guides the model through a multistep ontology construction pipeline. Each step refines the semantic structure, ensuring accuracy and coherence. To achieve the best performance, we tested several leading LLMs available on the market. We ultimately selected the one demonstrating advanced capabilities in handling extensive contexts and producing high-fidelity semantic representations. This model enables the Ontology Toolkit to capture subtle relationships and implicit meanings within documents, leading to precise and accurate ontologies.
2.2. Latest improvements
The latest version of Ontology Toolkit introduces major enhancements that make ontology generation smarter and more autonomous:
- Fully automated workflow:
In previous versions, users had to manually review and complete the list of classes suggested by the model and provide “competency questions” to refine relationships. Now, the process is entirely automated: users simply upload their documents and specify the use case, click once, and receive a fully generated ontology within a few hours at the most. - No document size or quantity limitations:
The system divides large document sets into smaller sections that are processed individually. This allows the Toolkit to handle vast amounts of text while maintaining fine-grained semantic analysis and ensuring complete coverage of all available information. - Improved prompts for higher-quality results:
After reviewing the limitations of earlier outputs, we rewrote and iterated the prompt design extensively. Among the improvements, we can mention that class and property names are now clearer and more consistent, hierarchies are more logically structured, and relationships are detected even when implicit, such as causal or hierarchical dependencies inferred from context. - Optimized reification:
The new version enhances property reification, the process of representing certain properties as entities themselves. This allows any type of information to have attributes itself or to be involved in properties. For example, in the CSRD case, a business acquisition can be represented by a property linking two organizations. But if it is represented as an entity thanks to reification, the ontology will be able to associate other information with it, such as the date or amount of the acquisition.
Users can now update an existing ontology, whether one previously generated by Ontology Toolkit or an external one, by incorporating new information extracted from fresh documents. This allows organizations to maintain living ontologies that evolve alongside their data and operations.
- Ontology update capability:
Users can now update an existing ontology, whether one previously generated by Ontology Toolkit or an external one, by incorporating new information extracted from fresh documents. This allows organizations to maintain living ontologies that evolve alongside their data and operations.
2.3. The ontology creation workflow
The new pipeline is meticulously structured into several sequential and integrated stages, designed to optimize both the quality and automation of ontology generation.
- Document ingestion: After the document parsing step, documents are processed in small, manageable units, one by one. This granular approach fosters finer semantic analysis, reducing the cognitive load on the LLM and enhancing precision in entity and relation extraction.
- Extracting semantic network (YAML): For each document, a detailed semantic network is generated in YAML format. This stage thoughtfully incorporates relation reification and accounts for types without directly instantiated entities, significantly enriching the initial semantic representation.
- Definition generation: Precise definitions for classes and properties are automatically generated, contributing substantially to the clarity and intelligibility of the ontology.
- Mapping attributes types: Attribute values are systematically replaced with appropriate data types (e.g., xsd:string, xsd:integer, xsd:date). This normalization is fundamental for data quality and subsequent exploitation.
- Build type hierarchy: A critical hierarchization step is implemented to structure types and classes in a logical and intuitive manner, thereby enhancing the ontology's navigability and expressiveness.
- Final ontology generation and formatting: All previously processed elements are consolidated into a coherent ontology. This ontology is then formatted and exported in Turtle (TTL) format, a W3C standard for RDF graph serialization, ensuring interoperability and reusability across diverse semantic environments.
You can download two ontologies created in this way as examples, one for pharmacology and the other for CSRD topics. Here is our page will all other ontologies you can download.
3. A key enabler for data exploration
3.1. Ontologies as the foundation of knowledge graphs
Ontologies are not an end in themselves, they are the conceptual backbone of knowledge graphs. A knowledge graph is an information representation system composed of nodes representing entities and edges representing relationships. It is the best way to extract impactful data, that is why Lettria has developed its own graph generation model, Perseus.
In practice, when Lettria automatically creates a knowledge graph from documentation with Perseus, the ontology is used to identify and structure information corresponding to the use case. It defines the entities, relationships and constraints that build the graph and give meaning to it. Without a coherent ontology, a knowledge graph is merely a set of unstructured connections. With one, it becomes a powerful framework for knowledge exploration, complex reasoning, and data interoperability.
In pharmacology, for example, the fact that a drug is contraindicated in certain conditions can be expressed in many ways, which can result in a messy graph. Thanks to the ontology, this case is already provided for with the relationship notRecommendedIn, and all information of this type in the documentation will be formalized in this manner.
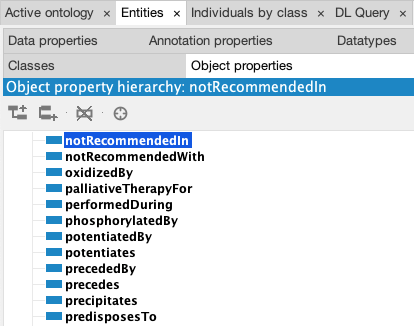
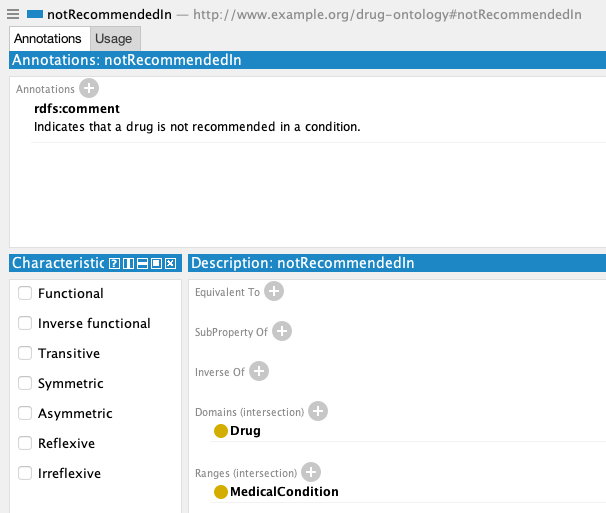
3.2. Querying data with Lettria’s GraphRAG
Once the ontology and the knowledge graph are automatically created, organizations can take full advantage of Lettria’s Knowledge Studio, a dedicated platform designed to chat with data. It is based on Lettria’s GraphRAG, a hybrid retrieval-augmented generation system using both a vector approach and graph representation. This solution allows users to query the data using an agent, in a conversational manner, using natural language.

Consider the following query, which relates to pharmacological documentation: “List all long-acting insulin analogs that are not recommended for the treatment of diabetic ketoacidosis”. GraphRAG's response is correct, and if we look at the triples (graph extracts) used to provide it, we can see that they do indeed contain the notRecommendedIn relationship mentioned above that enabled the information to be retrieved.
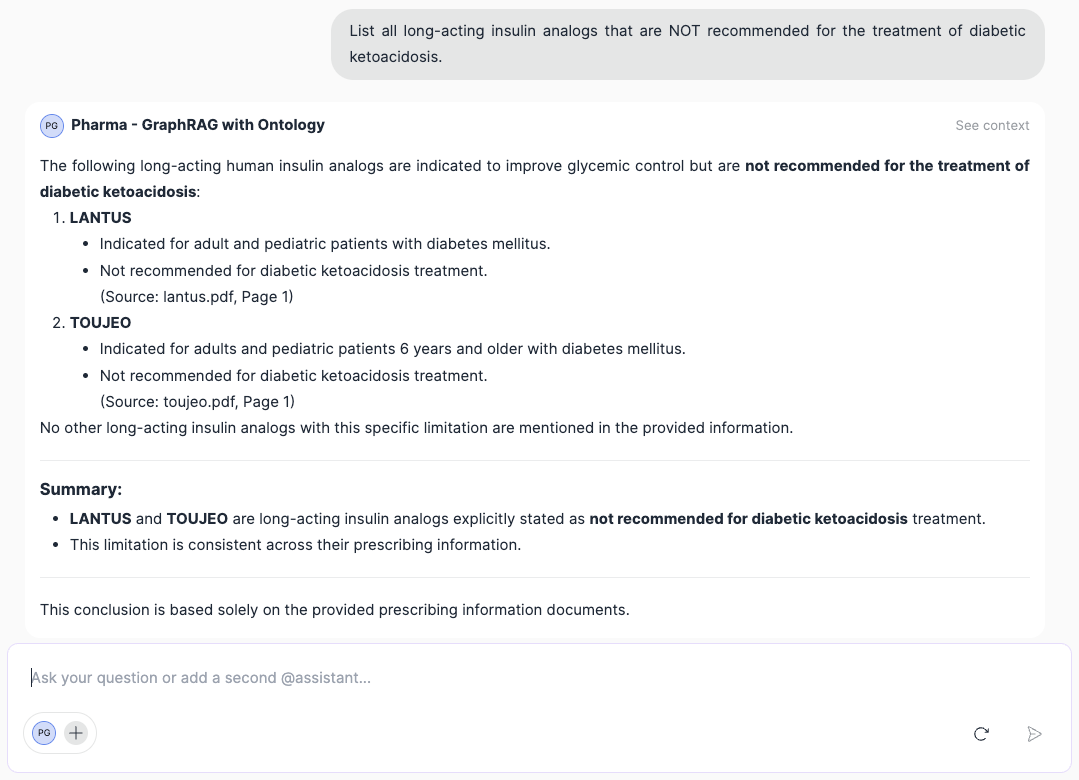
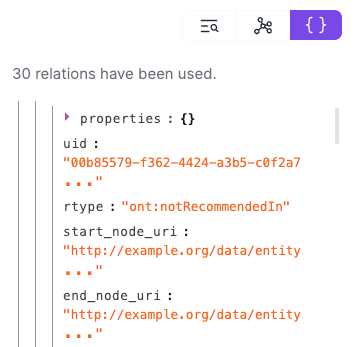
3.3. Expanding horizons with agentic AI
Lettria’s GraphRAG platform exemplifies one type of agentic AI: a conversational agent capable of interacting with structured knowledge. But the potential goes further: ontologies can support a wide range of autonomous systems, from decision-support agents to monitoring and recommendation tools.
By automating ontology creation, enterprises not only accelerate data exploration but also lay the semantic foundations for future generations of intelligent agents that can reason, act, and collaborate across domains.
Conclusion
Ontology Toolkit redefines ontology creation, transforming what was once a manual, highly specialized task into a fast, automated, and scalable process. By generating ontologies directly from corporate documents, it drastically reduces time-to-knowledge while ensuring accuracy, coherence, and adaptability. This automation democratizes access to semantic technologies, allowing teams to focus on leveraging insights rather than building frameworks from scratch.
As an initial step for using the Knowledge Studio platform, Ontology Toolkit becomes a cornerstone of enterprise data exploration and reasoning. Together, they enable organizations to query, connect, and understand their information through structured knowledge, paving the way for a new generation of agentic AI systems. Beyond efficiency, this approach strengthens the semantic foundations on which intelligent, explainable, and context-aware AI will thrive.
Frequently Asked Questions
Yes. Lettria’s platform including Perseus is API-first, so we support over 50 native connectors and workflow automation tools (like Power Automate, web hooks etc,). We provide the speedy embedding of document intelligence into current compliance, audit, and risk management systems without disrupting existing processes or requiring extensive IT overhaul.
It dramatically reduces time spent on manual document parsing and risk identification by automating ontology building and semantic reasoning across large document sets. It can process an entire RFP answer in a few seconds, highlighting all compliant and non-compliant sections against one or multiple regulations, guidelines, or policies. This helps you quickly identify risks and ensure full compliance without manual review delays.
Lettria focuses on document intelligence for compliance, one of the hardest and most complex untapped challenges in the field. To tackle this, Lettria uses a unique graph-based text-to-graph generation model that is 30% more accurate and runs 400x faster than popular LLMs for parsing complex, multimodal compliance documents. It preserves document layout features like tables and diagrams as well as semantic relationships, enabling precise extraction and understanding of compliance content.


.png)

.png)
.jpg)